Vapor モードとは#
Vapor モードの中国語直訳は蒸気モードです。
これは Vapor の GitHub リポジトリからの説明の一部です。

Vapor モードの開発のために、Vue チームは Vue3 のメインブランチからフォークした新しいリポジトリ「core-vapor」を作成しました。これは Vue の仮想 DOM なしのレンダリングモードを実現することを目的としています。
ここでVueの発展過程に詳しい方は、**「Vue1.0」は仮想 DOM のないバージョンではないか、これまでの年月でなぜ戻るのかと疑問に思うかもしれません。ここで、Vue の各大バージョンの「アーキテクチャの進化史」** を整理する必要があります。
Vue 1.0 量子もつれの細粒度バインディング#
これは Vue の初期の形が現れたマイルストーンであり、この時点では完全なリアクティブシステムは存在していませんでした。この時期に多くの人が話していたのは、データハイジャック + 依存収集に基づくリアクティブ実装の提案と、実装の詳細におけるWatcherとDepの二兄弟です。
理解していない方はこの「レンダリングフローチャート」を見てみると、Vue1.0 バージョンに対する理解を迅速に構築するのに役立ちます。
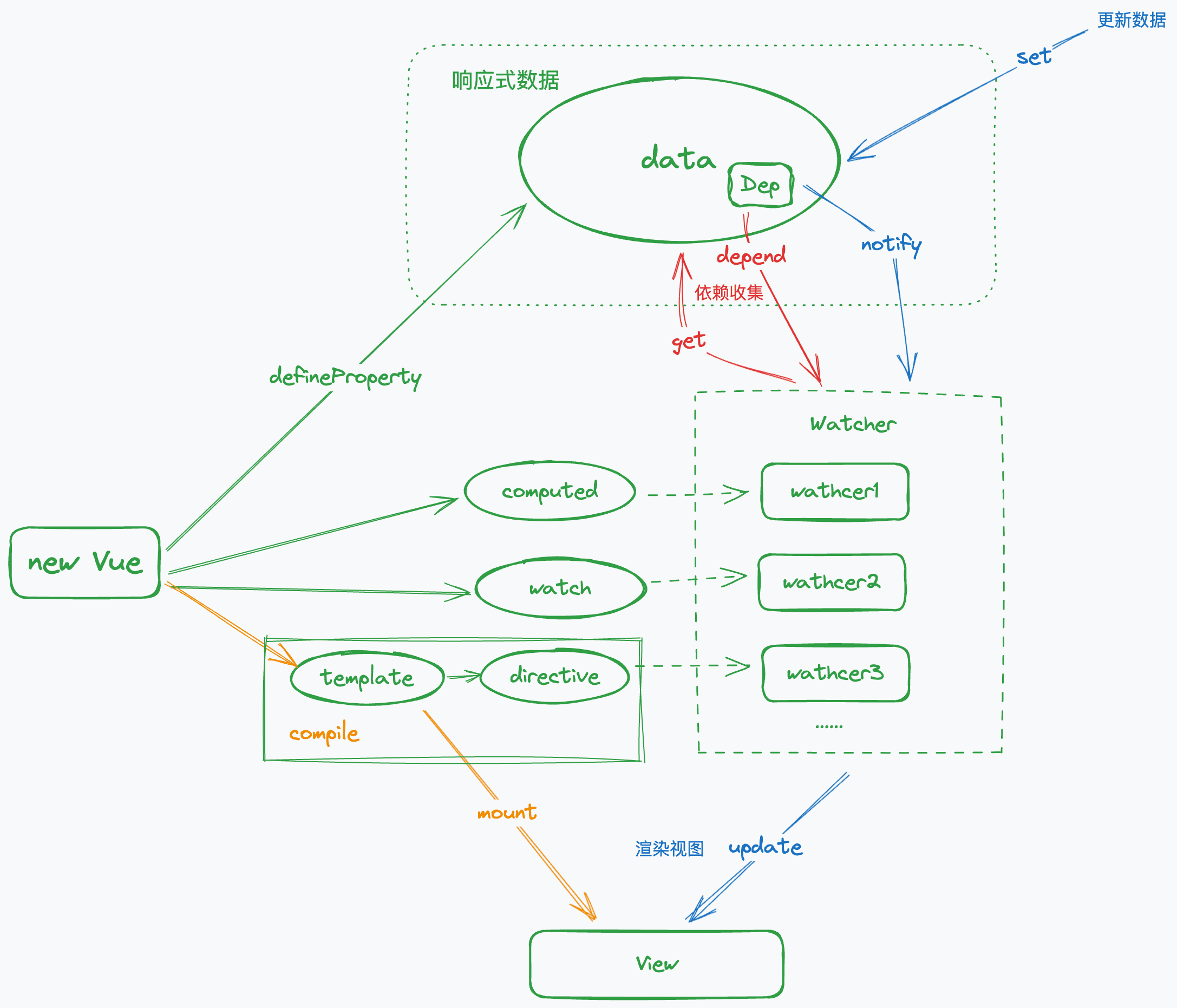
SFC(シングルファイルコンポーネント)がまだ存在しない時期、Vue は実質的に **「ランタイム」** フレームワークでした。上の図は、**new Vue ({...})** の後に発生する一連のプロセスを簡潔に示しています。
-
definePropertyを使用してデータハイジャックを実現し、目的はデータをプロキシし、すべてのデータに対するgetおよびset操作をインターセプトすることです。このプロセスは「getter/setter」化とも呼ばれます。
-
プロパティの「getter」の主な役割は依存を収集することです。ここでの「依存」とは、そのプロパティにアクセスするすべてのロジックを指し、計算プロパティやリスナー、テンプレート内のディレクティブやインターポレーション式である可能性があります。実装の観点から、これらの異なる依存は統一された概念であるWatcherに抽象化され、各プロパティのDepインスタンスに保存されます。
-
プロパティの「setter」は、データが変更されたときに、Depに収集されたWatcherに通知してビューを更新します。
全体のプロセスにおいて、Vue の依存収集の **「粒度」は非常に細かく、「リアクティブ」データにアクセスした場所はすべて「依存」** として収集されます。
上位の観点から言えば、「データ」と対応する「UI」がバインディング関係を形成しており、これが Vue が「ビューを更新」する際に非常に高い効率を持つ根本的な理由です。このバインディング関係は量子もつれのように、**「データ」が変化する際に「UI」** が通知を受けて更新を行います。
しかし、すべての事物には二面性があり、過度に細かい依存収集は利点でもあり短所でもあります。プロジェクトの規模が大きくなるにつれて、ランタイムはますます多くのWatcherとDepを生成し、過剰なメモリを消費し、ページのパフォーマンスに影響を与えます。
もしある提案が小規模プロジェクトに対して良好な **「パフォーマンス」** を提供できるだけであれば、それは明らかに「最適解」ではありません。
Vue 2.0 依存収集の粒度を調整し、仮想 DOM を導入#
大規模プロジェクトでより良いパフォーマンスを発揮するために、Vue2.0 バージョンは大きな調整を行いました。以下のフローチャートから、Vue のアーキテクチャシステムに直感的な変化があったことがわかります。
- 1.0バージョンに比べて、コンポーネントの概念が登場しました。
- 依存収集の粒度を「コンポーネントレベル」に調整し、1 つのコンポーネントが 1 つのWatcherとなります。
- 仮想 DOMを導入し、レンダリングプロセスの非常に重要な部分となりました。
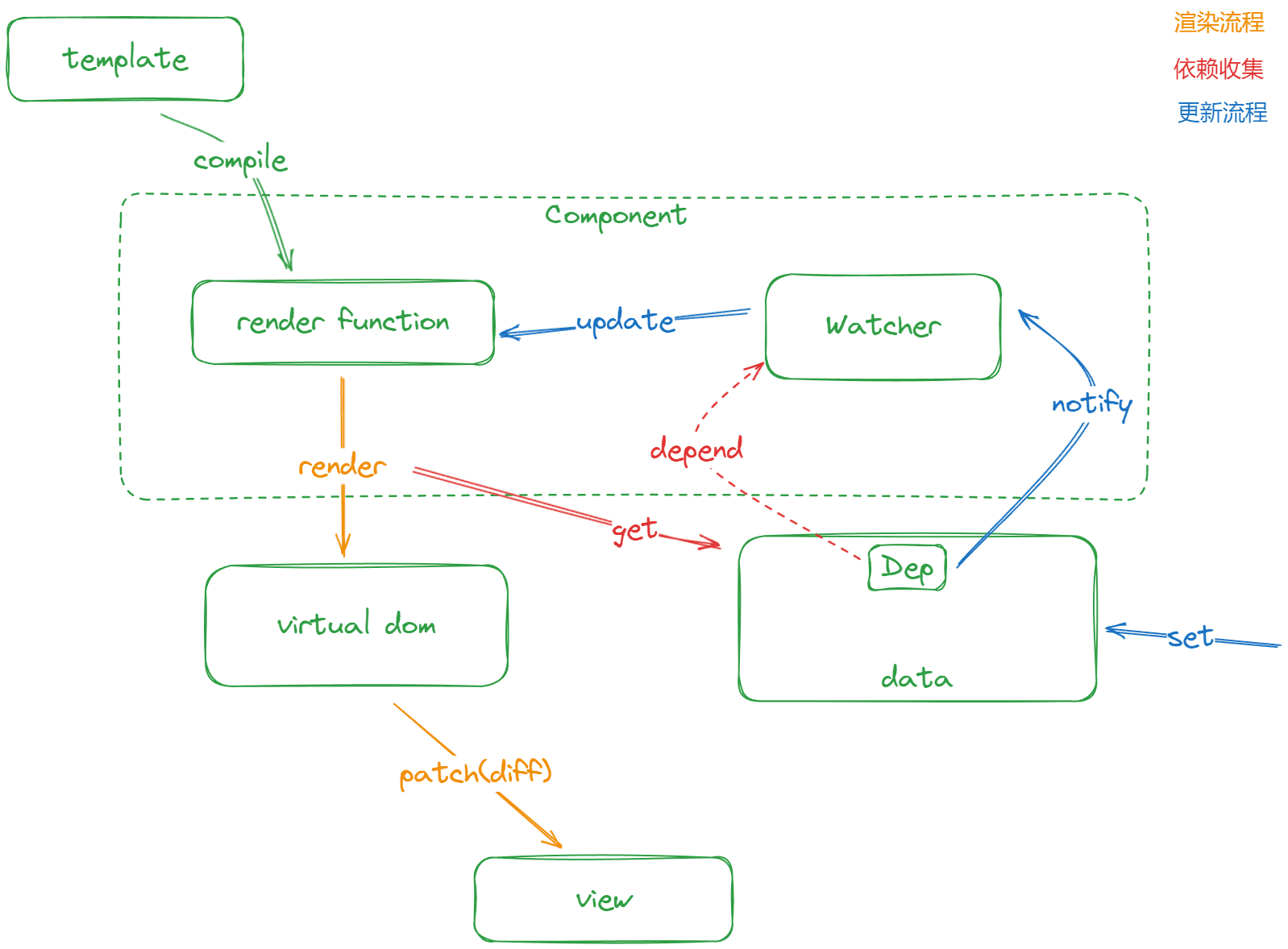
全体的に見て、「リアクティブ」データはもはやコンポーネント内部の「依存」に注目せず、データが変更されたときにはコンポーネントにのみ通知され、コンポーネントはdiffアルゴリズムを使用して「仮想 DOM」の変更部分を特定し、その部分を「リアル DOM」に更新します。これは本質的に時間を空間に換えるというトレードオフであり、**「ランタイム」の「更新効率」を適度に低下させることで、より少ない「メモリコスト」** を得ることを意味します。
同時期に Vue はSFC(.vue ファイル)も新たに追加しました。.vueファイルはフレームワークが提供する“魔法”であり、ブラウザに直接実行させることはできません。そのため、.vueを **.jsに変換することができるツールが必要です。このツールの核心はコンパイラ(compiler)であり、魔法を破るプロセスはコンパイル(compile)と呼ばれます。つまり、コンパイル後、.vueファイル内で書かれたv-if, v-for, インターポレーション式などの特性は、普通のjavascriptロジックに変換されます。templateはこの段階でrender** 関数に変換されます。
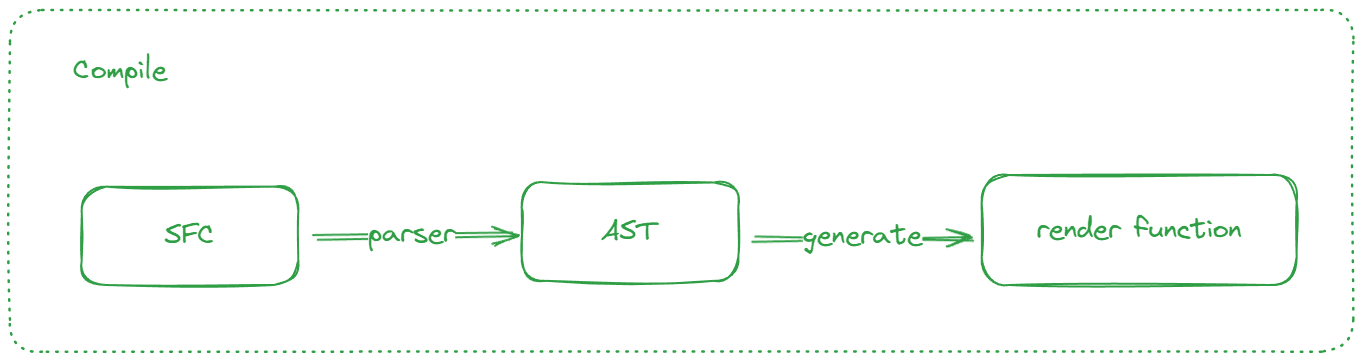
1.0 バージョンにもcompileプロセスは存在しましたが、行われることは大きく変わりました。
| compile | 1.0 | 2.0 |
|---|---|---|
| ステージ | ランタイム | コンパイル時 |
| 役割 | テンプレート内のディレクティブ、インターポレーションなどを解析して対応するロジックに変換し実行する | テンプレートを抽象構文木(AST)に解析し、レンダリング関数を生成する |
簡単な比較からもわかるように、コンパイルの実行ステージは完全に異なりますが、テンプレートの解析は依然として主旋律です。
ここまで来ると、Vue はアーキテクチャ上で極限の最適化を達成したように感じませんか?焦らずに、Vue 3.0 バージョンの進化を見た後に結論を出しましょう。
Vue 3.0 コンポジション API#
typescriptのフロントエンドでの台頭と、プロキシというメタプログラミング能力を代表する機能が主要なブラウザでサポートされるようになり、Vue3は完全に再構築された姿で登場しました。
また、オプションAPIのロジックが分散しすぎて、開発者が高い凝集性のあるコードを優雅に書くのが難しいという痛点を解決するために、React hooksの思想に触発されて、Vue3 もコンポジション APIを導入しました。この間にmixinのような提案もありましたが、いずれも多かれ少なかれ欠点がありました。
コンポジション APIモードでは、hooks を利用してビジネス機能をうまく組み合わせ、ロジックの凝集を実現できます。
新機能に加えて、Vue は細部の磨き上げにも多くの最適化を行いました。例えば、
- 事前文字列化
- 静的ノードの昇格
- パッチフラグ
注意深い方はすでに気づいているかもしれませんが、これらの最適化はコンパイル時の最適化に属し、ランタイムの最適化ではありません。なぜなら、ランタイムでは最適化できる方向性があまりなく、基本的にはパッチプロセスのdiffアルゴリズムに関連して行われるからです。
もう一度 Vue の Vapor について#
Vue の進化の過程を振り返った後、テーマであるVapor モードに戻ることができます。これは Vue がコンパイル時の最適化に関する研究を行っているものであり、もちろんSolidJSからの影響も受けています。
前述のように、Vue のアーキテクチャシステムに基づいて、ランタイムの最適化はほぼ仮想 DOMの中での変化をより早く見つけることにしかできません。
もし Vue1.0 の仮想 DOMがない形態に戻ると、当時の細粒度バインディングは変化を探す必要がなく、仮想 DOM も必要ありませんが、痛点は以下の通りです。
-
依存はランタイムで決定される。システムの初期化にはコンパイル段階でディレクティブなどを解析し依存を収集する必要があり、ファーストスクリーンのレンダリング時間が増加します。 -
細粒度の依存収集は大量のWatcherを生成し、より多くのメモリコストをもたらします。
今、視点を変えてみましょう。もし依存の決定時期をランタイムからコンパイル時に移すことができれば、コンパイル手段を通じて各リアクティブデータの変化時に実行する必要がある更新ロジックを生成することができ、上記の最初の痛点を解決できるのではないでしょうか。これがVapor モードの考え方です。
第二の痛点については、理論的には依存収集の粒度が粗から細に移行することで、必然的にメモリコストが増加します。この点についてVapor モードはどのように対処するのか、私たちは疑問を持ち、正式にリリースされた後にコールバックを待ちます。